Day 1 :
Keynote Forum
Ching Y Suen
Concordia University, Canada
Keynote: How well can computers recognize handwriting ?
Time : 09:05-09:45

Biography:
Ching Y. Suen is the Director of CENPARMI and the Concordia Honorary Chair on AI & Pattern Recognition. He received his Ph.D. degree from UBC (Vancouver) and his Master's degree from the University of Hong Kong. He has served as the Chairman of the Department of Computer Science and as the Associate Dean (Research) of the Faculty of Engineering and Computer Science of Concordia University. Prof. Suen has served at numerous national and international professional societies as President, Vice-President, Governor, and Director. He has given 45 invited/keynote papers at conferences and 200 invited talks at various industries and academic institutions around the world. He has been the Principal Investigator or Consultant of 30 industrial projects. His research projects have been funded by the ENCS Faculty and the Distinguished Chair Programs at Concordia University, FCAR (Quebec), NSERC (Canada), the National Networks of Centres of Excellence (Canada), the Canadian Foundation for Innovation, and the industrial sectors in various countries, including Canada, France, Japan, Italy, and the United States. Currently, he is the Editor-in-Chief of the journal of Pattern Recognition, an Adviser or Associate Editor of 5 journals, and Editor of a new book series on Language Processing and Pattern Recognition. Actually he has held previous positions as Editor-in-Chief, or Associate Editor or Adviser of 5 other journals. He is not only the founder of three conferences: ICDAR, IWFHR/ICFHR, and VI, but has also organized numerous international conferences including ICPR, ICDAR, ICFHR, ICCPOL, and as Honorary Chair of numerous international conferences.
Abstract:
Handwriting is one of the most important media of human communication. We write and read every day. Though handwriting can vary considerably in style and neatness, we recognize handwritten materials easily. Actually humans develop their writing skill in their childhood and gradually refine it throughout their lives. This paper examines ways humans write (from primary school to adult writing) and ways of teaching the computer to recognize (handwriting technology) what they produce from ancient (such as carved scripts, old books and documents) to modern times (such as immigration port-of-entry forms, cheques, payment slips, envelopes, and different kinds of notes and messages). Methods such a machine learning and deep classifier structures, extraction of space and margins, slant and line direction, width and narrowness, stroke connections and disconnections will be analyzed with large quantities of data. Both training procedures and learning principles will be presented to illustrate methodologies of enabling computers to produce robust recognition rates for practical applications in the office and in mobile phones. In addition, the art and science of graphology will be reviewed, and techniques of computerizing graphology will be illustrated with interesting examples.
Keynote Forum
Jean-Marc Ogier
University of La Rochelle, France
Keynote: Document analysis : a state of the art concerning a research field at the interesection of several disciplines
Time : 09:45-10:25

Biography:
Jean-Marc Ogier received his PhD degree in computer science from the University of Rouen, France, in 1994. During this period (1991-1994), he worked on graphic recognition for Matra Ms&I Company. From 1994 to 2000, he was an associate professor at the University of Rennes 1 during a first period (1994-1998) and at the University of Rouen from 1998 to 2001. Now full professor at the university of la Rochelle, Pr Ogier was the head of L3I laboratory (research lab in computer sciences of the university of la Rochelle) which gathers more than 120 members and works mainly of Document Analysis and Content Management. Author of more than 200 publications / communications, he managed several French and European projects dealing with document analysis, either with public institutions, or with private companies. Pr Ogier was Deputy Director of the GDR I3 of the French National Research Centre (CNRS) between 2005 and 2013. He was also Chair of the Technical Committee 10 (Graphic Recognition) of the International Association for Pattern Recognition (IAPR) from 2010 to 2015, and is the representative member of France at the governing board of the IAPR. He is now the general chair of the TC6, dealing with computational forensics of the International Association for Pattern Recognition. Jean-Marc Ogier has been the general chair or the program chair of several international scientific events dealing with document analysis (DAS, ICDAR, GREC, …) He was also Vice rector of the university of La Rochelle from 2005 to 2016, and president of VALCONUM association, which is an association aiming at forstering relations between industries and research organizations. He is now the president of the university of La Rochelle
Abstract:
Document engineering is the area of knowledge concerned with principles,tools and processes that improve our ability to create, manage, store, compact, access, and maintain documents. The fields of document recognition and retrieval have grown rapidly in recent years. Such development has been fueled by the emergence of new application areas such as the World Wide Web (WWW), digital libraries, computational forensics for document processing, and video- and camera-based OCR. This talk will address some recent developments in the area of Document Processing.
Keynote Forum
Jiankun Hu
University of New South Wales
Keynote: Multimedia security in big data era: Advances and open questions
Time : 10:45-11:25

Biography:
Jiankun Hu is full Professor at the School of Engineering and IT, University of New South Wales, Canberra, Australia. He has worked in the Ruhr University Germany on German Alexander von Humboldt Fellowship1995--1996; research fellow in Delft University of the Netherlands 1997-1998, and research fellow in Melbourne University, Australia 1998–1999. Jiankun's main research interest is in the field of cyber security including Image Processing/Forensics and machine learning where he has published many papers in high quality journals. He has served in the editorial board of up to 7 international journals including the top venue IEEE Transactions on Information Forensics and Security and served as Security Symposium Chair of IEEE flagship conferences of IEEE ICC and IEEE Globecom. He has served at the prestigious Panel of Mathematics, Information and Computing Sciences (MIC), ARC ERA(The Excellence in Research for Australia) Evaluation Committee.
Abstract:
Multimedia audio, video, and images have dominated the Internet traffic and also constituted the major applications in our daily life. Multimedia security has always been a concern in the community due to the issues of movie and music piracy, and privacy of medical images. Conventional cryptography can be applied to multimedia but additional challenges, such as real-time and efficiency, must be addressed. With emerging multimedia applications such as peer-to-peer streaming, and 3D data, multimedia is embracing a big data era where security and privacy are facing new challenges. Most multimedia security surveys have focused on the aspect of issues related to data communication. In the big data era, cloud computing is becoming a major platform which needs attracting due attention in the multimedia community. This keynote speech will provide a report on the advances in the field and open research questions will be discussed. The focus will be placed on efficient algorithms for emerging multimedia applications such a 3D imaging, and cloud based applications including digital rights management.
Keynote Forum
Teresa Chambel
Faculty of Sciences of the University of Lisbon, Portugal
Keynote: Video-based interactive and immersive media experiences
Time : 11:25-12:05

Biography:
Teresa Chambel is an Associate Professor in Department of Informatics, Faculty of Sciences, University of Lisbon in Portugal (DI-FCUL), and Senior Researcher of Human-Computer Interaction and Multimedia (HCIM) research line at LASIGE Lab. She graduated in Computer Science at FCUL, has a Master’s degree in Electrical and Computer Engineering, from IST, and a PhD in Informatics from FCUL. Before joining the LASIGE Lab, she was a member of the Artificial Intelligence Research Group, at LNEC, and the Multimedia and Interaction Techniques Group, at INESC. Her research interests include Multimedia and Hypermedia , Video and Hyper-video, HCI, Creativity, Immersion, Visualization, Accessibility, Cognition and Emotions, Wellbeing, Interactive TV, e-Learning and Digital Art. In these areas, she has been teaching, researching, supervising students, publishing conference and journal papers and book chapters, and organizing events.
Abstract:
By appealing to several senses, video and other rich media have the potential to engage viewers perceptually, cognitively and emotionally. Immersive media and immersive video in particular, can go beyond, with a stronger impact on users’ emotions and their sense of presence and engagement. Immersion may be influenced by sensory or perceptual modalities surround effect, and vividness through resolution, associated with the sense of presence, the viewer's conscious feeling of being inside the virtual world or alternate reality; and by participation and social immersion in the media chain, increasing the sense of belonging. Technology is increasingly supporting capturing, producing, sharing and accessing video-based information from users' own perspectives and experiences on the internet, in social media, and through video on demand services in interactive TV and the web. We have been witnessing an increase in the amount of content and range of devices for capturing, viewing and sensing, allowing richer and more natural multimodal interactions, and offering tremendous opportunities for immersion. These developments have been promoting the emergence of a new participatory paradigm and enabling new perceptual immersive experiences. In this presentation, I will present insights from human studies, addressing dimensions like perception, cognition, and emotions, along with design and technological approaches for immersion, illustrated in interactive and immersive video-based applications, grounded in our own projects and research.

- Virtual Reality| Animation and Simulations | Computer Vision & Pattern Recognition |Computer Graphics & Applications| Image Processing | Artificial Intelligence| 3D analysis, representation and printing |

Chair
Ching Y Suen
Concordia University, Canada

Co-Chair
Mort Naraghi-Pour
Louisiana State University, USA
Session Introduction
Mort Naraghi-Pour
Louisiana State University, USA
Title: Context-based unsupervised ensemble learning and feature ranking

Biography:
Mort Naraghi-Pour received his Ph.D. degree in electrical engineering from the University of Michigan, Ann Arbor, in 1987. Since August 1987, he has been with the School of Electrical Engineering and Computer Science, Louisiana State University, Baton Rouge, where he is currently the Michel B. Voorhies Distinguished Professor of Electrical Engineering. From June 2000 to January 2002, he was a Senior Member of Technical Staff at Celox Networks, Inc., a network equipment manufacturer in St. Louis, MO. Dr. Naraghi-Pour received the best paper award from WINSYS 2007 for a paper co-authored with his student, Dr. X. Gao. Dr. Naraghi-Pour’s research and teaching interests include wireless communications, broadband networks, information theory, and coding. He has served as a Session Organizer, Session Chair, and member of the Technical Program Committee for numerous national and international conferences.
Abstract:
In ensemble systems, several experts, which may have access to possibly different data, make decisions which are then fused by a combiner (meta-learner) to obtain a final result. Such Ensemble-based systems are well-suited for processing Big-Data from sources such as social media, in-stream monitoring systems, networks, and markets, and provide more accurate results than single expert systems. However, most existing ensemble learning techniques have two limitations: i) they are supervised, and hence they require access to the true label, which is often unknown in practice, and ii) they are not able to evaluate the impact of the various data features/contexts on the final decision, and hence they do not learn which data is required. In this paper we propose a joint estimation-detection method for evaluating the accuracy of each expert as a function of the data features/context and for fusing the experts’ decisions. The proposed method is unsupervised: the true labels are not available and no prior information is assumed regarding the performance of each expert. Extensive simulation results show the improvement of the proposed method as compared to the state-of-the-art approaches. We also provide a systematic, unsupervised method for ranking the informativeness of each feature on the decision making process.
Ghyslain Gagnon
École de technologie supérieure, Université du Québec, Montreal, Canada
Title: The Circuit of Bachelard: a lumino kinetic interactive artwork Le Circuit de Bachelard: a lumino kinetic interactive artwork at École de technologie supérieure
Time : 12:05-12:30

Biography:
Ghyslain Gagnon received the Ph.D. degree in electrical engineering from Carleton University, Canada in 2008. He is now an Associate Professor at École de technologie supérieure, Montreal, Canada. He is an executive committee member of ReSMiQ and Director of research laboratory LACIME, a group of 10 Professors and nearly 100 highly-dedicated students and researchers in microelectronics, digital signal processing and wireless communications. Highly inclined towards research partnerships with industry, his research aims at digital signal processing and machine learning with various applications, from media art to building energy management.
Abstract:
This peculiar combination of illuminated electro-technical elements honors the intellectual journey of philosopher Gaston Bachelard (1884-1962), who interlaced forward-thinking ideas underlying the complex interaction of reason and imagination, an important contribution to inspire us a society deeply marked by scientific and artistic creativity. Permanently installed in the main tunnel at École de technologie supérieure, Montreal, Canada, this interactive artwork reminds future engineers of the importance of the rationale-intuitive bilaterality in any technological innovation.
The animation of lighting creates routes of running light blobs through the tunnel. Since the lighted tubes share the space with actual electrical and HVAC pipes, the lighting dynamics gives the impression of flow of useful elements (electricity, network data, air) in the building. A microphone is hidden in an electrical box at the center of the tunnel to allow interactive control. A sound recognition algorithm is used to identify blowing sounds: when users blow in an opening in this electrical box, the flow of light is accelerated, a symbol of the contribution of engineers in such technical systems.
The artwork was designed as an innovation platform, for students to add elements to the installation in the future, allowing increased interactivity. This platform was successfully tested in 2015 by a team who created a luminous tug of war game in the tunnel, with players using their mobile phones as a controlling device.
The installation was nominated at the Media Architecture Biennale awards ceremony, Sydney, 2016.
Mounîm A. El-Yacoubi
University of Paris-Saclay, Palaiseau, France
Title: Sequential modeling and recognition of human gestures and actions
Time : 13:45-14:10

Biography:
Mounîm A. El-Yacoubi (PhD,University of Rennes, France, 1996) was with the Service de Recherche Technique de la Poste (SRTP) at Nantes, France, from 1992 to 1996, where he developed software for Handwritten Address Recognition that is still running in Automatic French mail sorting machines. He was a visiting scientist for 18 months at the Centre for Pattern Recognition and Machine Intelligence (CENPARMI) in Montréal, Canada, and then an associated professor (1998-2000) at the Catholic University of Parana (PUC-PR) in Curitiba, Brazil. From 2001 to 2008, he was a Senior Software Engineer at Parascript, Boulder (Colorado, USA), a world leader company in automatic processing of handwritten and printed documents (mail, checks, forms). Since June 2008, he is a Professor at Telecom SudParis, University of Paris Saclay. His main interests include Machine Learning, Human Gesture and Activity recognition, Human Robot Interaction, Video Surveillance and Biometrics, Information Retrieval, and Handwriting Analysis and Recognition.
Abstract:
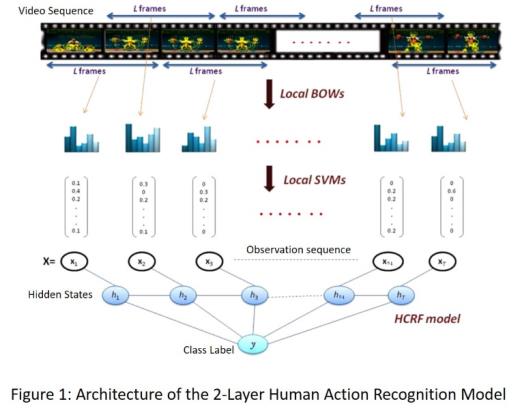
Human action recognition (HAR) is an active research field, driven by the dramatic price decrease of powerful digital cameras, storage and computing machines, and by the potential of HAR for designing smart engines making sense of today ubiquitous video streams. In video surveillance, for instance, HAR can help determining abnormal events in public facilities. For e-health, HAR may be harnessed as an assistive technology monitoring people with autonomy loss. Recognizing human actions, however, is challenging. Known variability factors such intra-class and inter-class variability, are much more adverse as they involve additional structural variability that is hard to cope with. Besides, actions are not communicative in general, which hinders relevant information acquisition and tracking. Others variability sources include viewing direction and distance w.r.t acquisition sensor, lighting conditions, etc. In this talk, we review the problem of human action and gesture recognition in general. After discussing the challenges above, we propose a new approach that focuses on video sequential input modeling. The modeling is based on a two-layer SVM – Hidden Conditional Random Field (SVM-HCRF) in which SVM acts as a discriminative front-end feature extractor. First, a sliding window technique segments the video sequence into short overlapping segments, described each by a local Bag-of-Words (BOW) of interest points. A first-layer SVM classifier converts each BOW into a vector of class conditional probabilities. The sequence of these vectors serves as the input observation sequence to HCRF for actual human action recognition. We show how this hierarchical modeling optimally combines two different sources of information characterizing motion actions: local motion semantics inferred by SVM, and long range motion feature dependencies modeled by HCRFs at a higher level. Finally, we show how these models can be extended to the problem of conjoint segmentation and recognition of a sequence of actions within a continuous video stream.
Nicole Vincent
Paris Descartes University, France
Title: Blur in text documents: Estimation and restoration
Time : 14:10-14:35

Biography:
Nicole Vincent has her expertise in Pattern Analysis Document. She is a Full Professor at Paris Descartes University, in SIP research group (Systèmes Intelligents de Perception) at LIPADE Lab. She completed her PhD in Computer Science in 1988 and became Full Professor in 1996. She worked in numerous projects in pattern recognition, signal and image processing and understanding and video analysis with particular interest for document image analysis domain. She has supervised more than 35 students and collaborated with many labs, institutions and companies.
Abstract:
Document transfers are more and more often achieved in an electronic way and images come from mobile camera. Then, image quality varies a lot and is no more mastered. An important first step in next processing is to evaluate the quality, blur is adding noise. In this context, blur model is difficult to apply as it has different origins, defocusing or movement blur. Models are often suited for one type of blur and when blur is uniform on the whole page. Then some learning can enable to solve a reverse problem. Some other approach can be developed that adapts itself locally to the image content. On a document, all parts are not equivalent and textual parts are more important from blur point of view than figure parts or background parts; for example, blur is based on the ambiguity coming from the pixel color associated with text part and background. Thus, fuzzy model is suited to interpret the color level distribution in the neighborhood of text contours. Fuzzy clustering leads to two classes and a fuzzy score can be defined at a pixel level from the membership values, the results can be propagated at higher levels. The interest of the approach is two-fold, quality can be estimated and the contrast in the document can be improved. Evaluation can be performed from different points of view, from an aesthetical point of view, that is human perception or in a quantitative way. The approach can be direct or indirect. In document analysis, optical character recognition is, most often, the main objective on which relies the future processing and the understanding phase. Then, improving OCR recognition rate is one way to measure the de-blurring process. Comparison with other methods can be performed on public databases, in our case on DIQA database.


Nuria Medina-Medina
University of Granada, CITIC-UGR, Spain
Title: Designing video games
Time : 14:35-15:00

Biography:
Nuria Medina received her Ph.D. in computer science from the University of Granada (UGR) in 2004, proposing an adaptive and evolutionary model for hypermedia systems. Nowadays, she belongs to the direction team of the Research Centre for Information and Communications Technologies (CITIC-UGR) and is professor at the Department of Computer Languages and Systems at this Spanish University where she directs a project that implements educational games in Andalusian school classrooms (P11-TIC7486).
Abstract:
The video game industry continues with its high rate of growth and, correspondingly, video games are a product present in most of the first-world households. Thousands of people around the planet work in the development of games and billions of players enjoy these multimedia creations; however, from an engineering perspective, critical issues in the design of these video games are not are being sufficiently considered. Therefore, an academic effort to identify and analyze which are the keys of a good design and the possible design solutions in each particular context should be done in relation to the productive and unstoppable world of video games. With this aim, taxonomies, guidelines and design patterns are different approaches in which we have been working. On the other hand, serious games must be specially attended since the serious propose involved in the game implies the need to design and integrate no-ludic contents and the collaboration with no-technical professionals during all the process. In the first case, it is essential to introduce the serious elements in the game so that they remain hidden within the ludic contents. In the second case, an adequate language is crucial to facilitate the communication between the technical team and the subject-domain experts (educators, doctors, etc.). Particularly, our group has been researching to achieve the indispensable balance between the ludic component and the instructive component in educational video games. As a result, our design methodology establishes a ‘divide and conquer' approach where the game challenges and the educational goals are designed and interrelated making use of graphics notations, which allow modeling of the artefacts of the educational video game in a comprehensible form for all the stakeholders. As a study case, an educational adventure to promote reading comprehension has been developed and is being evaluated.

Stylianos (Stelios) Asteriadis
University of Maastricht, the Netherlands
Title: Computer Vision and Machine Intelligence to the service of societal needs
Time : 15:00-15:25
 Asteriadis")
Biography:
Stylianos Asteriadis, PhD, MSc, is Assistant Professor at the University of Maastricht, the Netherlands. Stylianos Asteriadis received his PhD from the School of Electrical and Computer Eng. of National Technical University of Athens. His research interests lie in the areas of affective computing, visual computing, machine learning, and human activity recognition, while he has published more than 40 journal and international conference papers in the aforementioned fields. Currently, he is the Principal Investigator for the University of Maastricht in two H2020 collaborative projects (H2020-PHC-2015 Health project ‘ICT4Life- Advanced ICT systems and services for integrated care’ and H2020 ICT-20-2015 ‘MaTHiSiS- Technologies for better human learning and teaching’), while he is a reviewer and program committee member for several journals and conferences in his field
Abstract:
Recent advances in the areas of computer vision, artificial intelligence and data analysis are giving rise to a new era in human-machine interaction. A computer (or a machine, in general) should not be seen as a passive box that just processes information but, instead, today it can – and, actually, should - be seen as a device that can act as a companion, an active tutor or a health coach that can interpret our personalized needs, emotions and activities. Coupling human-machine interaction with ambient assisted living and visual computing is now escaping the tight limits of research laboratories and university departments and real products see their way into the market. We discuss about our current research in the use of computer vision and latest advances in machine intelligence to the benefit of societal needs and, in particular, in the areas of education and health. We will present the pipeline and methods used in our research, as well as the bottlenecks met, both from a technical point of view and a functional one. Subsequently, we will give an overview of computer vision techniques and ambient assisted living technologies utilized for human emotion understanding and activity recognition. Results, within the frame of our current work, with the use of ANNs for learning, in an unsupervised manner, personalized patterns in emotion and/or activity understanding, user profiling and system adaptation will be shown and discussed during the talk.
Arata Kawamura
Osaka University, Japan
Title: Image to sound mapping and its processing techniques
Time : 15:25-15:50

Biography:
Arata Kawamura completed BE and ME degrees in Electrical and Electronic Engineering at Tottori University, Japan, in 1995 and 2001, respectively, and DE degree at Osaka University, Japan, in 2005. He was an Assistant Professor at Osaka University from 2003 to 2012. He is currently an Associate Professor at Graduate School of Engineering Science, Osaka University, Japan. His main researches are in the area of Speech Signal Processing. Recently, his research interests include image processing, especially image to sound mapping. He developed a transformation method from an image to an understandable human speech signal in 2016. He is studying to process a sound as an image, or an image as a sound.
Abstract:
Sound spectrogram is useful to visually analyze time-varying characteristics of a sound. Since the sound spectrogram can be treated as an image, we can process the sound spectrogram by using image processing techniques. Such interesting techniques have been applied in music transcription, musical instruments sound separation, noise reduction and so on. Conversely, we can produce a sound signal from an image which is treated as a sound spectrogram. This technique is called as image to sound mapping. In the image to sound mapping, the most important parameters are spectral phase, playback time and frequency bandwidth. The spectral phase decides sound type or tone color. The playback time is the time for providing the single image, and frequency bandwidth decides each pitch of sinusoid to make the sound. Since the main purpose of the mapping sound is to bear the image as a sound, we should carefully make the mapping sound under a common condition with respect to these parameters. Addition to it, we should have some knowledge of a filtering effect for the mapping sound, because the sound is received at sensors after passing through a certain transfer function from a loudspeaker to the sensors. I focus on filtering or modifying a mapping sound from an image, and investigate its image-reconstruction capability. Firstly, we review image to sound mapping techniques. Secondly, for a mapping sound, we apply three basic operations of the signal processing, i.e., multiplication, delay, and addition. Thirdly, we discuss the basic filtering effects obtained from low-pass filters, high-pass filters, and band-pass filters. These processing results are intuitively acceptable. Then, we also investigate FIR and IIR echo effects. After that, some modulation effects such as amplitude modulation are discussed. Finally, on a sound to image mapping method, useful drawing techniques are presented.
Jehan Janbi
Taif University, KSA
Title: PANOSE-A: Encoding Arabic Fonts based on design characteristics
Time : 16:10-16:35

Biography:
Jehan Janbi is an assistance professor in Computer Science and Information Technology College at Taif University. She got her bachelor of Computer Science from King Abdul-Aziz University, Jeddah, Saudi Arabia. She started her Academic career journey as TA lab supervisor and research assistance in Computer Science department in Qassim University. She upgraded her academic level and got her Master and PhD from Concordia University, Montreal, Canada. Her research area is in text and font recognition, mainly for Arabic script. She worked on encoding Arabic digital font’s design characteristics into a number composed of several digits where each digit represents specific design characteristics. This will enhance manipulating and searching fonts based on their appearance.
Abstract:
In digital world, there are thousands of digital fonts makes selecting an appropriate font is not an intuitive issue. Designers can search for a font like any other file using general information such as name and file format. But for document design purposes, the design features or visual characteristics of fonts are more meaningful for designers than font file information. Therefore, representing fonts’ design features by searchable and comparable data would facilitate searching and selecting a desirable font. One solution is to represent a font’s design features by a code composed of several digits. This solution has been implemented as a computerized system called PANOSE-1 for Latin script fonts. It is used within several font management tools as an option for ordering and searching fonts based on their design features. It is also used in font replacement processes when an application or an operating system detects a missing font in an immigrant document or website. This research defined a new model, PANOSE-A, to extend PANOSE-1 coverage to support Arabic characters. The model defines eight digits in addition to the first digit of PANOSE-1which indicates the font script and family type. Each digit takes value between 0-15 where each value indicates a specific variation of its represented feature. Two digits of the models describe the common variations of the weight and contrast features, which are two essential features in any font design. Another four digits describe the shape of some strokes that usually vary in their design between fonts, such as the end shape of terminal strokes, the shape of the bowl stroke, the shape of curved stroke and the shape of rounded strokes with enclosed counter. The last two digits describe the characteristics of two important vertical references of the Arabic font design which are tooth and loop heights.
Tsang-Ling Sheu
National Sun-Yat-Sen University, Taiwan
Title: Dynamic RB allocations using ARQ status reports for multimedia traffic in LTE networks
Time : 16:35-17:00

Biography:
Tsang-Ling Sheu received the Ph.D. degree in computer engineering from the Department of Electrical and Computer Engineering, Penn State University, University Park, Pennsylvania, USA, in 1989. From Sept. 1989 to July 1995, he worked with IBM Corporation at Research Triangle Park, North Carolina, USA. In Aug. 1995, he became an associate professor, and was promoted to full professor in Jan. 2006 at the Dept. of Electrical Engineering, National Sun Yat-Sen University, Kaohsiung, Taiwan. His research interests include wireless networks, mobile communications, and multimedia networking. He was the recipient of the 1990 IBM outstanding paper award. Dr. Sheu is a senior member of the IEEE, and the IEEE Communications Society.
Abstract:
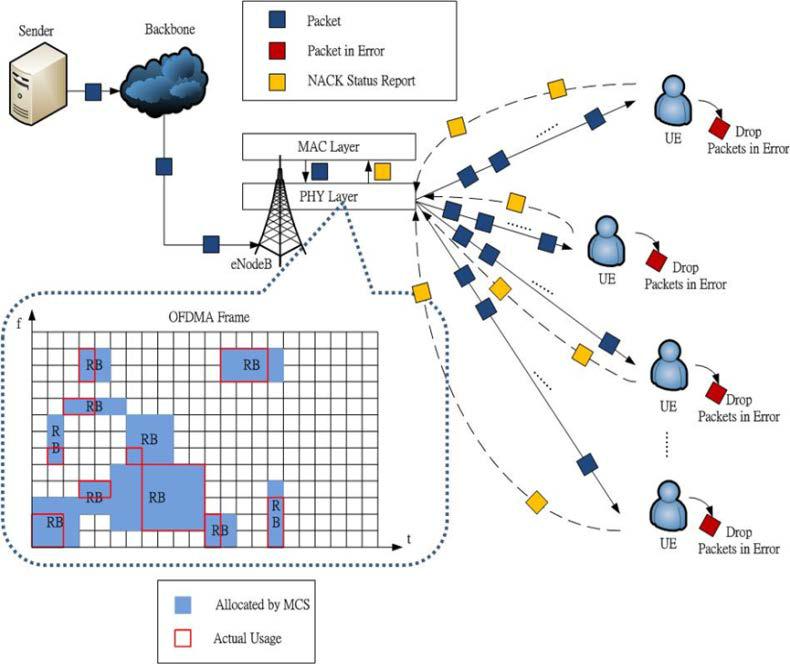
This paper presents a dynamic resource blocks (RBs) allocation scheme for multimedia traffic in LTE networks by utilizing automatic repeated request (ARQ) status report, in which an user equipment (UE) reports erroneous packets to an evolved-node base station (eNodeB). From the status report, eNodeB will compute the amount of successfully received packets per unit time for each UE. Therefore, eNodeB can properly allocate RBs which is exactly the requirement of each UE. Moreover, we consider three different multimedia traffic types (audio, video, and data) with different priorities. Our proposed scheme can alter the modulation determined by automatic modulation and coding (AMC) scheme such that the utilization of an orthogonal frequency division multiplexing access (OFDMA) frame can be substantially increased. To prevent the starvation of data traffic which has the lowest priority, we set an upper bound of employed RBs for audio and video traffic. At last, we perform NS-3 simulation to demonstrate the superiority of the proposed scheme. The simulation results show that our proposed scheme can perform much better than the traditional AMC scheme in terms of RBs utilization, blocking rate of UEs, and the number of successfully connected UEs. Particularly, when in a high noise environment and a large number of UE under an eNodeB, the proposed scheme can achieve relatively smaller blocking rates for QoS-guaranteed multimedia traffic, such as video and audio.
Yea-Shuan Huang
Huang-Hua University, Taiwan
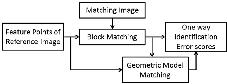
Title: Feature-point geometrical face recognition with local invariant features
Time : 17:00-17:25

Biography:
Abstract:
Maria Jose Arrojo
University of A Coruña, Spain
Title: Procedures for searching information on the Internet. Role of designs based on Artificial Intelligence

Biography:
Maria Jose Arrojo is reader at the Department of Humanities of the University of A Coruña. She has the recognition as Titular Professor in the field of Communication Sciences. She is member of the research group that works on the philosophy and methodology of the Sciences of the Artificial. She has published papers analyzing communication sciences from the perspective of the sciences of the artificial, in general, and the design sciences, in particular. Arrojo has been working off research projects on bounded rationality and the sciences of design supported by the Spanish Ministry related to scientific research and technological innovation. Since 2003 she is the co-director of the Post-degree studies in Audiovisual Production and Management at the University of A Coruña. She was an advisor to the Institute for Foreign Trade of the Government of Spain, in strategic issues of the internationalization of the audiovisual sector (2005-2011).
Abstract:
The procedures for finding information on the Internet are mediated by three main aspects. First, the mode of representation of knowledge, because the search is done by a conceptual content that guides the search designs. Second, the specific procedures of heuristics, that is, the patterns or rules that agents or machines must follow so that they have adequate programming to achieve the results they are looking for. Third, there is the task of the agents, who are the ones who select the aims, choose the procedures and evaluate the results.
All of this is done in the procedures for searching information on the Internet. This is possible by designs based on Artificial Intelligence. The study of these designs requires research from the Artificial Sciences. In this sense, this paper starts from the base of the Communication Sciences conceived as Applied Sciences of Design, therefore of the Sciences of the Artificial. Thus, the epistemological point of departure is the representation of knowledge that set aims, which in this case are forms of information on the Internet (YouTube, Snapchat, etc.). Then the methodological component comes, specific ways of finding the information based on the objectives sought with the designs. Thirdly, we have the ontological factor, where agents intervene to achieve the results, based on the representation of knowledge and search methods
It is assumed here that, to design the machine learning procedure, the starting point of the designs is in Artificial Intelligence. To that end, it is necessary to be clear what the objectives of the search are, to reach the aims drawn with the design. Only then do the machines finish doing what they have been programmed for. The agents intervene at the beginning, for the design aims, and at the end, to evaluate the results obtained.
Chengjiang Long
Kitware Inc, USA
Title: Collaborative Active Learning from Crowds for Visual Recognition

Biography:
Chengjiang Long received his Ph.D. degree from Stevens Institute of Technology in 2015. Currently, he is a computer vision researcher in the computer vision team at Kitware, a leader in the creation and support of state-of-the-art technology, providing robust solutions to academic and government institutions, such as DARPA, IARPA, and the Army, as well as private corporations worldwide. Prior to joining Kitware, he ever worked at NEC Labs America and GE Global Research in 2013 and 2015, respectively. To date, he has published more than 20 papers in reputed international journals and conferences, and has been searving as a reviewer for top international journals (e.g., TIP, MM, MVAP and TVCJ) and conferences (e.g., ICCV, ECCV, ACCV, BMVC and ICME).
Abstract:
Active learning is an effective way to relieve the tedious work of manual annotation in many applications of visual recognition. The vast majority of previous works, if not all of them, focused on active learning with a single human oracle. The problem of active learning with multiple oracles in a collaborative setting has not been well explored. Moreover, most of the previous works assume that the labels provided by the human oracles are noise free, which may often be violated in reality.
To solve the above-mentioned issues, we proposed two models (i.e., a distributed multi-labeler active learning model and a centralized multi-labeler active learning model) for collaborative active visual recognition from the crowds, where we explore how we can effectively model the labelers’ expertise in a crowdsourcing labeling system to build better visual recognition models. Both two models are not only robust to label noises, but also a principled label quality measure to online detect irresponsible labelers. We also extended the centralized multi-labeler active learning model from binary cases to multi-class cases and also incorporate the idea of reinforcement learning to actively select both the informative samples and the high-quality annotators, which better explores the trade-off between exploitation and exploration.
Our collaborative active learning models have been validated in the real-world visual recognition benchmark datasets. The experimental results strongly show the validity and efficiency of the two proposed models.

Biography:
Abstract:
Syed Afaq Ali Shah
The University of Western Australia, Australia
Title: Deep learning for Image set based Face and Object Classification
Biography:
Syed Afaq Ali Shah has done PhD in 3D computer vision (feature extraction, 3D object recognition, reconstruction) and machine learning in the School of Computer Science and Software Engineering (CSSE), University of Western Australia, Perth. He was holder of the most competitive Australian scholarships, which include Scholarship for International Research Fee (SIRF) and Research Training Scheme (RTS). He has published several research papers in high impact factor journals and reputable conferences. Afaq has developed machine learning systems and various feature extraction algorithms for 3D object recognition. He is the reviewer for IEEE Transactions on Cybernetics, Journal of Real Time Image Processing and IET Image Processing journal.
Abstract:
I shall present a novel technique for image set based face/object recognition, where each gallery and query example contains a face/object image set captured from different viewpoints, background, facial expressions, resolution and illumination levels. While several image set classification approaches have been proposed in recent years, most of them represent each image set as a single linear subspace, mixture of linear subspaces or Lie group of Riemannian manifold. These techniques make prior assumptions in regards to the specific category of the geometric surface on which images of the set are believed to lie. This could result in a loss of discriminative information for classification. The proposed technique alleviates these limitations by proposing an Iterative Deep Learning Model (IDLM) that automatically and hierarchically learns discriminative representations from raw face and object images. In the proposed approach, low level translationally invariant features are learnt by the Pooled Convolutional Layer (PCL). The latter is followed by Artificial Neural Networks (ANNs) applied iteratively in a hierarchical fashion to learn a discriminative non-linear feature representation of the input image sets. The proposed technique was extensively evaluated for the task of image set based face and object recognition on YouTube Celebrities, Honda/UCSD, CMU Mobo and ETH-80 (object) dataset, respectively. Experimental results and comparisons with state-of-the-art methods show that our technique achieves the best performance on all these datasets.

Biography:
David Zhang graduated in Computer Science from Peking University. He received his MSc in 1982 and his PhD in 1985 in Computer Science from the Harbin Institute of Technology (HIT), respectively. From 1986 to 1988 he was a Postdoctoral Fellow at Tsinghua University and then an Associate Professor at the Academia Sinica, Beijing. In 1994 he received his second PhD in Electrical and Computer Engineering from the University of Waterloo, Ontario, Canada. He is a Chair Professor since 2005 at the Hong Kong Polytechnic University where he is the Founding Director of the Biometrics Research Centre (UGC/CRC) supported by the Hong Kong SAR Government in 1998. He also serves as Visiting Chair Professor in Tsinghua University, and Adjunct Professor in Peking University, Shanghai Jiao Tong University, HIT, and the University of Waterloo. He is Founder and Editor-in-Chief, International Journal of Image and Graphics (IJIG); Founder and Series Editor, Springer International Series on Biometrics (KISB); Organizer, the 1st International Conference on Biometrics Authentication (ICBA); Associate Editor of more than ten international journals including IEEE Transactions and so on. So far, he has published over 10 monographs, 400 journal papers and 35 patents from USA/Japan/HK/China. According to Google Scholar, his papers have got over 34,000 citations and H-index is 85. He was listed as a Highly Cited Researcher in Engineering by Thomson Reuters in 2014 and in 2015, respectively. Professor Zhang is a Croucher Senior Research Fellow, Distinguished Speaker of the IEEE Computer Society, and a Fellow of both IEEE and IAPR.
Abstract:
In recent times, an increasing, worldwide effort has been devoted to the development of automatic personal identification systems that can be effective in a wide variety of security contexts. As one of the most powerful and reliable means of personal authentication, biometrics has been an area of particular interest. It has led to the extensive study of biometric technologies and the development of numerous algorithms, applications, and systems, which could be defined as Advanced Biometrics. This presentation will systematically explain this new research trend. As case studies, a new biometrics technology (palmprint recognition) and two new biometrics applications (medical biometrics and aesthetical biometrics) are introduced. Some useful achievements could be given to illustrate their effectiveness.

Biography:
We are also accepting proposals for Symposia and Workshops on all tracks. All proposals must be submitted to multimedia@conferenceseries.net
Abstract:

Biography:
David Xu is tenure associate professor at Regent University, specializing in computer 3D animation and movie special effects. He got MFA Computer Graphics in 3D Animation from Pratt Institute in NY. He has served as a senior 3D animator in Sega, Japan; a senior CG special effector in Pacific Digital Image Inc., Hollywood; and as a professor of animation in several colleges and universities where he developed the 3D animation program and curriculum. He has been a committee member of the computer graphics organization Siggraph Electronic Theater, where he was recognized with an award for his work.
Abstract:
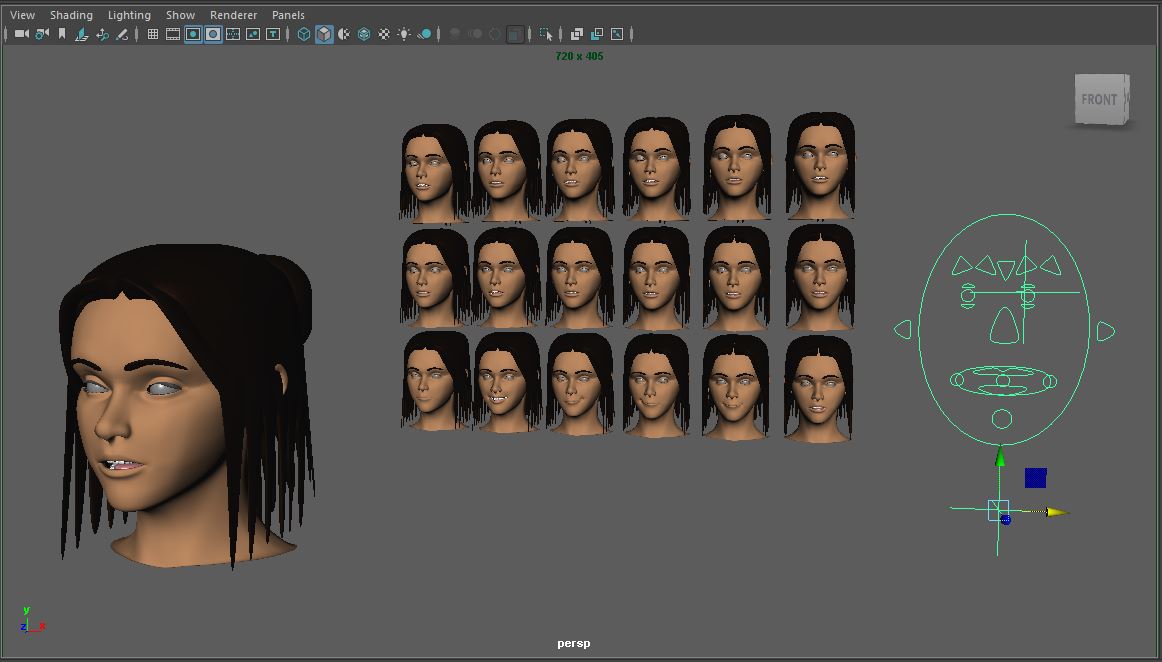
Blend shapes, also known as morph target animation, are a powerful way of deforming geometry such as human face to create various facial expressions, from happy to sad. In this presentation, after overviewing Autodesk Maya blend shapes, their features and work flow, Professor Xu will demonstrate and discuss how to create a more efficient workflow by combining blend shapes with Maya’s Set Driven Key features, and how to create a more complex facial animation with advanced blend shape techniques and features. Concepts and techniques such as blend shape deformer, Blend Shape node, Tweak node, Set Driven Key, morph target animation, vertex position, and more will be introduced and demonstrated. Finally, Professor Xu will discuss the advantages and disadvantages of using morph target animation over skeletal animation in 3D facial animation.