Md. Haidar Sharif
International University of Sarajevo, Bosnia and Herzegovina
Title: How to track unknown number of individual targets in videos?
Biography
Biography: Md. Haidar Sharif
Abstract
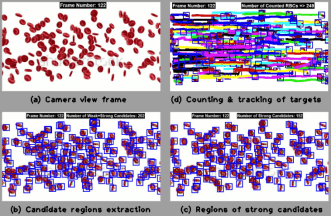
Target tracking, which aims at detecting the position of a moving object from video sequences, is a challenging research topic in computer vision. Obstacles in tracking targets can grow due to quick target motion, changing appearance patterns of target and scene, non-rigid target structures, dynamic illumination, inter-target and target-to-scene occlusions, and multi-target confusion. As selection of features affects the tracking results, it is eventful to select right features. Feature selection is closely related to the target representation. A target shape can be represented by a primitive geometric shape including rectangle, ellipse, circle, square, triangle, and point [1]. The efforts of tracking targets or objects in videos as efficient as possible are not new [1, 2, 3, 4]. A vast majority of the existing algorithms primarily differ in the way they use image features and model motion, appearance and shape of the target. In this discussion, we will discuss how to track unknown number of individual targets in videos by leveraging a spatiotemporal motion model of the movers. We will address our innovative idea [4] of how to extract the candidate regions, irrespective of movers' number in the scenes, from the silhouetted structures of movers' pixels. Silhouettes of movers obtained on capturing the local spatiotemporal motion patterns of movers, we can generate candidate regions in the candidate frames in a reflex manner. Candidate frame means a frame where a target template would be matched with one of its available movers. Weak candidate regions are deleted with the help of phase-correlation technique, while strong candidate regions are fed into a combined tracking algorithm of Hungarian process and Kalman filter. Since targets are searched in the strong candidate regions only, some well-established concepts (e.g., integral images [5] and brute force) are left out. Henceforth, search process gets super rapid as compared to brute force since comparative runtime reduced from O(n!) to O(n3) with problem size n. Complete trajectories of individual targets in 3D space are resulted in asymptotic runtime of O(n3). Figure 1 shows a sample output of our framework.